News
Johns Hopkins APL’s Cyclone Aims to Improve Collaborative Human-Machine Decision-Making

From left, Cyclone co-principal investigator (PI) Nina Cohen, PI Nick Kantack and team member Nathan Bos. Not pictured: Timothy Endres, James Everett and Corey Lowman.
Credit: Johns Hopkins APL/Craig Weiman
As human-machine teaming becomes prevalent, collaborative tasks between people and computers have grown more consequential. The elevated stakes associated with performing a medical diagnosis or operating missiles in battle call for improved teamwork and decision-making between human and machine. Artificial intelligence (AI) researchers at the Johns Hopkins Applied Physics Laboratory (APL) in Laurel, Maryland, developed an AI agent that aims to address this need.
Making AI More Human
Nick Kantack, an AI researcher and software developer at APL, created one such AI agent called Cyclone and trained it to play the cooperative card game Hanabi through a unique learning process. Kantack moved away from the standard self-play approach to training AI, where agents play against copies of themselves, and instead adopted an approach where Cyclone learned by playing against copies of human players.
“I adopted this strategy: If Cyclone can play like a human, it’ll probably play well with humans,” Kantack said. “In doing so, I hoped to improve collaboration between human and machine teammates in Hanabi.”
Hanabi players work together to achieve this goal: organize a random draw of numbered and colored cards into five separate lines, comprising five cards each, that are grouped by colors and sequentially ordered. The catch is that players cannot look at their own cards and must glean information about their hand from limited clues given by other players.
The game is an effective platform to understand how to improve the cooperation between AI systems and human operators in the field. For that reason, the Laboratory’s Intelligent Systems Center (ISC) challenged staff members to develop AI agents that played well with humans. The ISC serves as APL’s focal point for research and development in AI, robotics and neuroscience, as the Laboratory seeks to fundamentally advance the employment of intelligent systems for the nation’s critical challenges.
Four AI agents were developed by different APL teams as part of the ISC challenge, and those agents played 40 games of Hanabi with a human team member, an arrangement known as hybrid-play. Notably, Cyclone’s average score was higher than the score achieved by human-only teams and higher than that of its nearest hybrid-play competitor, earning it the challenge win.
“Games and competitions are a great way to push the boundaries of AI research. APL, and the ISC in particular, focuses on creating competitions where the underlying AI breakthroughs could apply to real-world applications for our sponsors,” explained ISC Chief Bart Paulhamus. “We were attracted to the Hanabi competition because human-AI collaboration is a major area of interest across most, if not all, of APL’s mission areas.”
Modeling and Optimizing Human Decisions
Cyclone is directed to pay attention to what Kantack calls human-preferred factors, or elements that humans pay attention to when deciding to put down or discard a card. For instance, when Kantack is playing Hanabi, he prioritizes gathering information tokens, which allow a player to provide clues to other team members. Kantack listed all his preferred factors and attributed a numerical value to quantify the importance he placed on each. He then fed that list and those values to Cyclone, which used Kantack’s self-identified factors and values to create a virtual copy of Kantack as a Hanabi player.
Kantack then directed Cyclone to analyze a database comprising 500 of his Hanabi moves. After analyzing this database, Cyclone created another virtual copy of Kantack. To create this second, more accurate model of Kantack’s playing style, Cyclone had to adjust Kantack’s self-reported values.
“This was a shocking result, because it meant that Cyclone was gaining insight into my play style that I didn’t even have,” Kantack said.
Once Kantack saw that Cyclone was able to model his decision-making with 70% accuracy, he directed the agent to create more copies. “Cyclone played just over 500,000 games with copies of my virtual self, exploring play styles that led to higher scores,” he said.
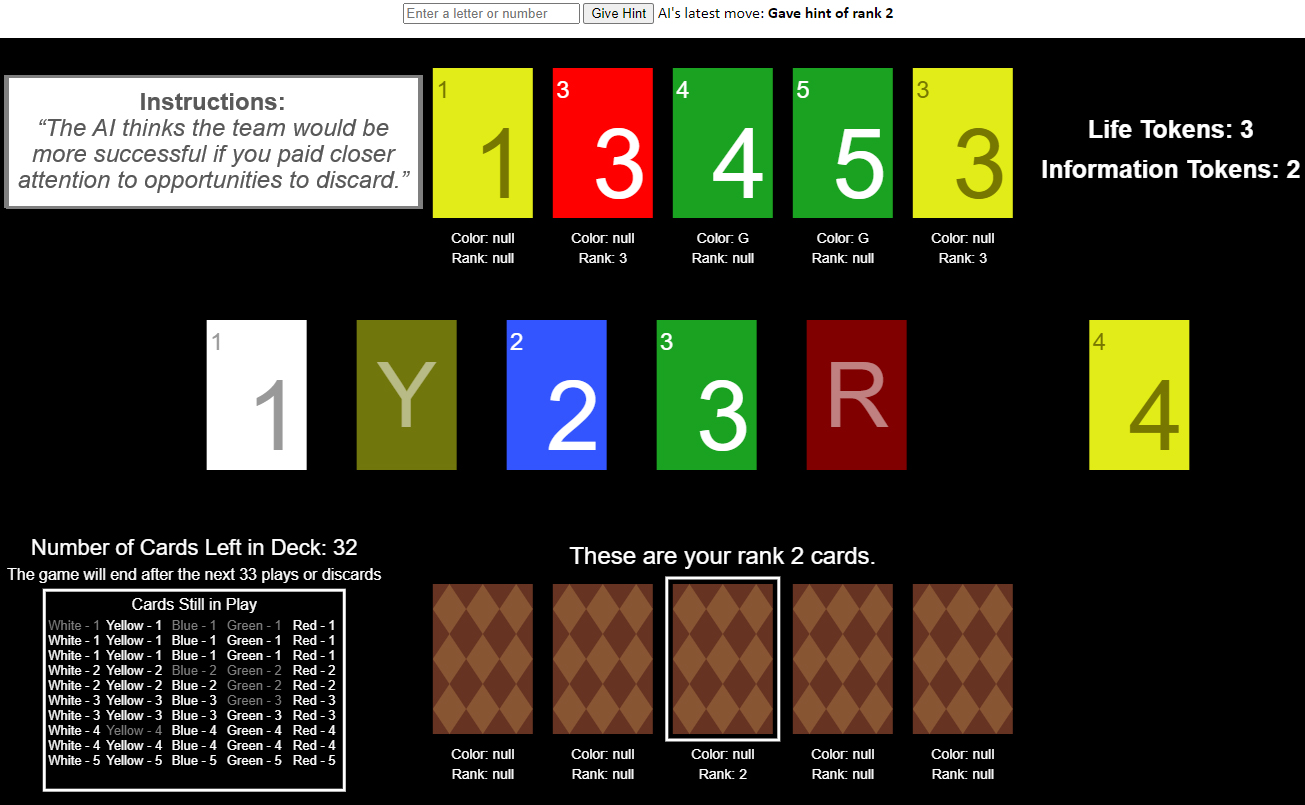
The team believed that by providing instruction focused on improving a human player’s reasoning, Cyclone could become the ultimate teammate to a human. By the end of its experiments, the team found that the instruction group showed significantly greater improvement in its decision making compared to those that received other kinds of feedback.
Credit: Johns Hopkins APL
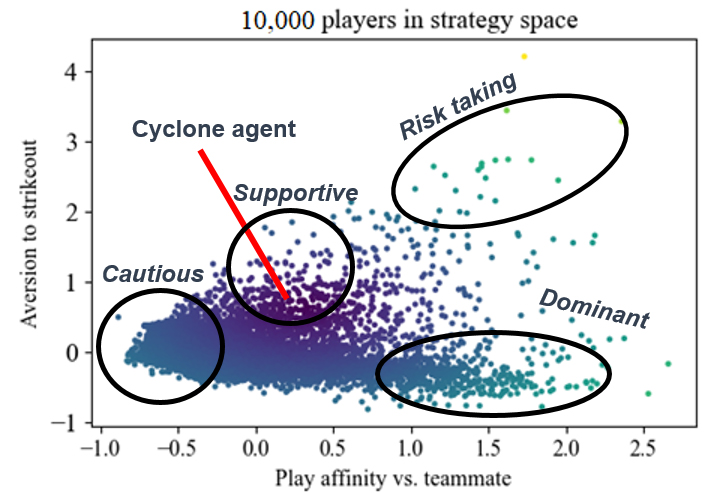
In addition to modeling the play style of its Hanabi human teammate, Cyclone analyzes the strength of a player’s move. By identifying 12 events that could impact the final score of a Hanabi game, Cyclone is able to predict how a single move might affect and multiply the likelihood of those 12 turning points. Such a decision model allowed the team to categorize over 10,000 human players of online Hanabi games, in addition to characterizing Cyclone’s play style.
Credit: Johns Hopkins APL