Press Release
Johns Hopkins APL Developing Standards to Enable Better Brain Analysis
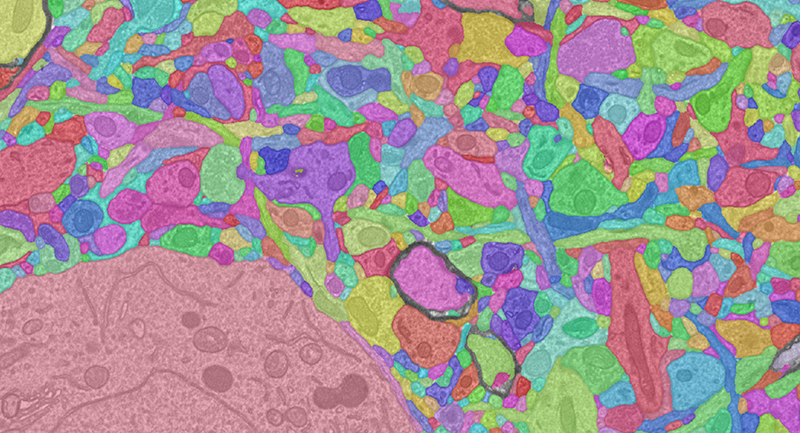
A high-resolution electron microscopy, segmentation and morphological reconstruction of cortical circuits within the visual cortex of a mouse. Captured as part of the Machine Intelligence from Cortical Networks (MICrONS) program to map the function and connectivity of cortical circuits, using high-throughput imaging technologies.
Credit: BossDB
In the last decade, the neuroscience community has collected increasingly large data sets, using high-resolution imaging modalities such as electron microscopy and X-ray microtomography, to better understand the structure and anatomy of nervous systems. However, there is significant variability in how the data is being collected and annotated, limiting the ability of researchers to effectively leverage this large, public investment.
Researchers at the Johns Hopkins Applied Physics Laboratory (APL) in Laurel, Maryland, are leveraging the Laboratory’s systems engineering and scientific expertise to unite diverse stakeholders and develop standards for these high-resolution data sets. These data include fascinating maps of the brain at unprecedented scale, where scientists can directly observe and study individual connections between cells at the resolution of only a few nanometers.
“We will significantly amplify neuroscience research investments by ensuring data and analysis products are comparable and reproducible,” says Will Gray Roncal, an electrical engineer in APL’s Research and Exploratory Development Department (REDD) and the principal investigator for BENCHMARK (Big-Data Electron-microscopy for Novel Community Hypotheses: Measuring And Retrieving Knowledge), funded by a foundational $1.3 million research project grant from the National Institutes of Health (NIH).
BENCHMARK is a key project in NIH’s BRAIN Initiative, aimed at revolutionizing the understanding of the human brain. By accelerating the development and application of innovative technologies, the agency says, researchers will be able to produce a new dynamic picture of the brain that, for the first time, will show how individual cells and complex neural circuits interact in both time and space. It is expected that the application of these tools and technologies will ultimately lead to new ways to treat and prevent brain disorders.
Previous NIH BRAIN Initiative efforts have established standards for the collection of data in light microscopy, functional magnetic resonance imaging, electrophysiology and genomics, Gray Roncal notes. But until now, the creation of a similar set of guidelines has not been attempted for large-scale structural data such as electron microscopy (EM) and X-ray microtomography (XRM).
The team plans to disseminate these standards in multiple phases, which will include integrating them into BossDB, a public neuroscience database built and maintained by APL that holds the most diverse set of electron microscopy brain imagery in the world.
“By combining data storage, data processing and cross-data-set querying within a single ecosystem, we aim to enable a new level of secondary science on rich data sets generated by the neuroscience community, helping to ensure democratization of science for research teams that might not be able to collect their own,” said REDD’s Brock Wester, who manages BossDB and serves as a senior key member of the BENCHMARK team.
Another goal of the effort is to develop guidelines for annotation, metadata and other products derived from EM and XRM data to ensure interoperable processing tools and consistent results from downstream processing of that data. “For example, we can compare structural wiring motifs across worms, flies, mice and humans — and create the tools and paradigms to allow other people to build on these queries and develop their own questions,” Gray Roncal explained.
Participants in APL’s Cohort-based Integrated Research Community for Undergraduate Innovation and Trailblazing — or CIRCUIT — program, including Morgan Sanchez, now pursuing a doctorate at Harvard, and Dymon Moore, an APL GEM fellow and graduate student at Drexel University, have played a critical role in developing the initial metadata query engine prototype.
A significant part of building these standards is consensus building among the community, said Erik Johnson, a computer scientist and engineer in REDD who serves as the project manager for BENCHMARK.
“It is an incredibly exciting frontier, but some of the questions that we’re asking are going to be these almost deceptively simple ones, in the sense that we’ve been studying neuroscience for maybe a century and half and we can’t answer the question of ‘how many synapses are there in the Drosophila mushroom body?’ or ‘how many synapses are there in layer two of a mouse cortex?’” Johnson said.
“Only in the last decade have we gotten to the point where we even ask those questions,” he continued. “And with this effort, we hope to get everything into a format where anyone can get these answers. I think the questions will only get more exciting the further we get into it.”
Additional reading: There has been great progress in standardizing interfaces for large-scale spatial image data, but more work is needed to standardize annotations, especially metadata associated with neuroanatomical entities. In “Connectomics Annotation Metadata Standardization for Increased Accessibility and Queryability” — published in May in Frontiers in Neuroinformatics — Sanchez, Moore and co-authors share key design considerations and a use case developed for metadata for a recent large-scale data set.
This material is based on work supported by National Institutes of Health grants R01MH126684, R24MH114799 and R24MH114785, under the NIH BRAIN Initiative Informatics Program.