The CBRNE-SF knowledge base contains the interconnected series of actions an adversary would likely take when producing, weaponizing, or employing a WMD. In many cases, there are several different synthetic approaches to produce a WMD, so the knowledge base must contain all possible approaches. The knowledge base is not meant to provide precise step-by-step instructions for producing, weaponizing, or employing a WMD; instead, it provides a road map to the most essential actions that present opportunities for discovery. Additionally, it leverages a diverse range of authoritative sources. Subject-matter experts (SMEs) consulted online databases, specialized dictionaries, reference texts, peer-reviewed journals, and other trusted resources to develop each process. Whenever possible, our workflows are grounded in, and enriched by, peer-reviewed literature.
To codify the steps an adversary would use to carry out some activity or set of activities, we developed the following lexical constructs: pathways, processes, activities, observables, and signatures.
A pathway is the interconnected series of actions that are performed and lead to some intended outcome. In CBRNE-SF, this takes the form of a unidirectional flowchart comprising processes and activities.
A process allows for collecting related activities used to get to a specific end state. These processes can be nested as subprocesses in a bigger overall process.
An activity defines the lowest level of discrete action modeled in the pathway. Activities contain all the relevant information required for that activity to be completed successfully and, subsequently, all the information that would allow the activity’s discovery. These activities are assembled in processes that themselves can be nested in higher-level processes. Similar to Unified Modeling Language (UML),1 we provide constructs in the data model that allow for decisions to be made when multiple choices are available in carrying out a set of activities and also allow capture of activities that can be performed asynchronously. Supplemental information, such as activity descriptions, references, drawings, and illustrations, is also captured and associated as appropriate. Within the CBRNE-SF, processes and activities can be reused to gain efficiency in modeling new threats. A SME can leverage these previously modeled items containing hundreds or thousands of nodes simply by copying them. This saves considerable time and standardizes the processes for commonly used precursors, as well as allows for quick updates to the models as the threat landscape changes.
A key innovation for the construction of the data model is the idea that the pathways themselves should be instantiations of ontological classes. This led to the development of a pathway modeling ontology, with the resulting behavior that, as the pathways are constructed, the processes, activities, decisions, etc., end up as connected nodes in the knowledge graph. This allows for a fully interconnected graph that can be easily traversed in a query. This enables the kinds of analysis described later in this article.
A pathway allows for activities to be associated with the set of items, or observables, required to carry out the activity successfully, and each of these observables in turn can be associated with many signatures (e.g. spectral). These signatures are data representations of how the observable “appear” when analyzed by a specific sensor.
Here, similar to the construction of the pathways, each association of an observable to an activity or signature to observable, expands the knowledge graph by creating additional nodes and edges in the data model.
Observables can most simply be thought of as anything that can be sensed (e.g., smelled, tasted, seen, heard, touched). Observables are divided into three distinct groups:
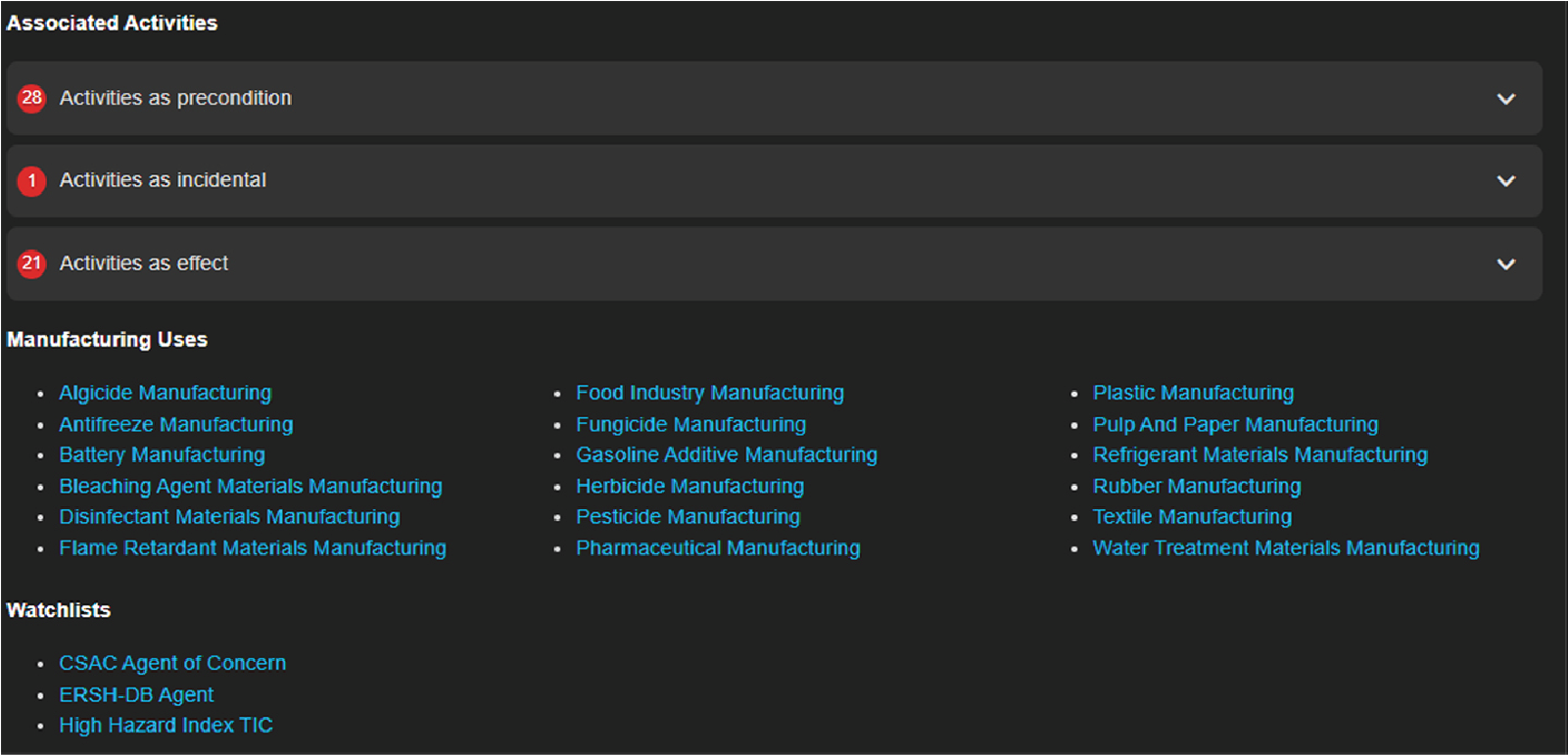
- Preconditions: Observables that must be present for the activity to succeed
- Effects: Observables produced as a result of performing the activity, regardless of whether they are detected (Example: A reaction produces chlorine, but a mechanism is used to remove the chlorine from the waste stream. Chlorine is still called out as an effect.)
- Incidentals: Observables that are not absolutely required for an activity but are likely to be present given what is typically used to conduct the activity (Example: In the chemistry domain, many reactions are carried out in a fume hood. The fume hood, while ideal for safety reasons, is not absolutely required and is therefore called out as incidental because it may or may not be present. If present, it does provide significant clues to the type of activities being conducted.)
Each observable contains the following information if available from a vetted source:
- Definition/description
- Nefarious and legitimate manufacturing uses
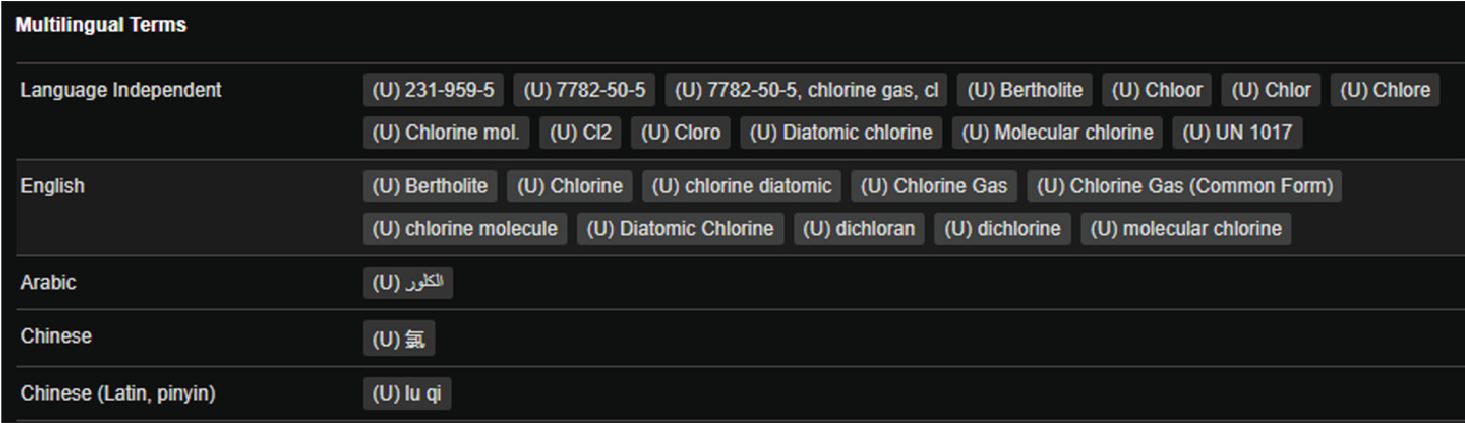
- English, foreign-language, and language-independent alternative labels, synonyms, and colloquialisms
- Description of entity relationships (e.g., potential uses)
- Classification
- Source information (e.g., bibliographic citations)
- Pictures/illustrations
For biological and chemical entities, the following information is also included:
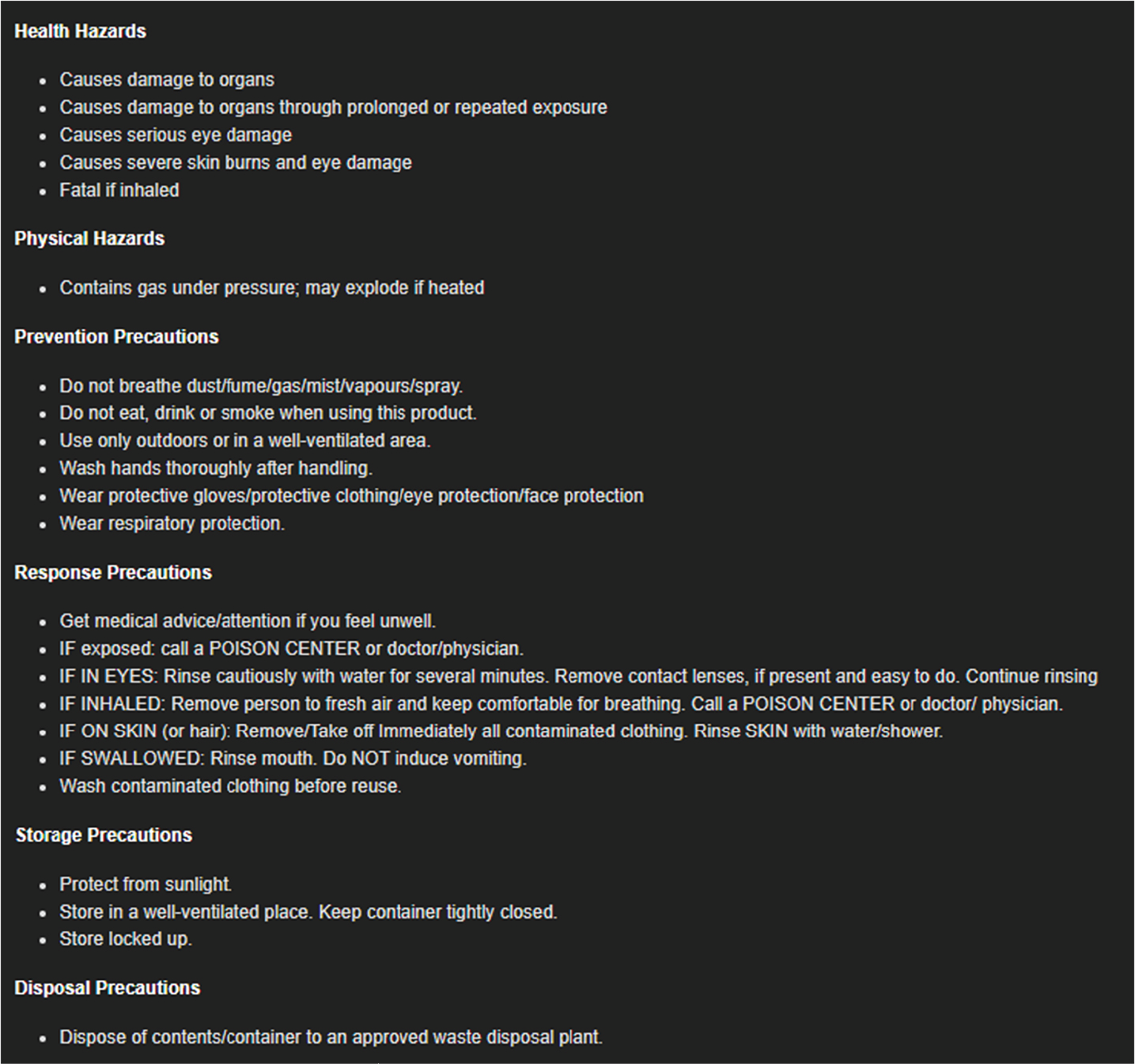
- Health and hazard statements, where appropriate
- Physical properties, where appropriate
- Industrial uses
- Cross-references to chemical and biological datasets
- Machine-readable identifiers (e.g., Chemical Abstract Service registry numbers)
Observables, like processes and activities, are modeled as instances of classes defined within ontologies tailored to specific CBRNE-SF domains. These ontologies are built using the Resource Description Framework (RDF) and the Web Ontology Language (OWL), standards endorsed by the World Wide Web Consortium (W3C).2,3 RDF structures data as a graph composed of subject–predicate–object triples, each expressing a simple fact (e.g., Bill isFatherOf Steve). These statements are linked to form dynamically growing graphs, enabling rich semantic modeling, inference, and graph analytics, capabilities particularly well suited for representing adversarial activity.
To enhance semantic precision and structure, RDF is extended through RDF Schema (RDFS) and OWL, which introduce class- and property-based constructs for building ontologies. In this framework, classes define conceptual entities, and properties express the relationships among them, together forming a flexible, machine-readable vocabulary for each domain of interest.
The CBRNE-SF knowledge base is fundamentally a composition of such ontologies. These are not limited to taxonomic hierarchies; rather, concepts can assert facts about other concepts, creating a richly interconnected semantic model. To ensure consistency and expressiveness across domains, the domain-specific ontologies are aligned under foundational upper ontologies. These upper ontologies provide additional structure and rigor to the knowledge representation, though their detailed description lies beyond the scope of this overview.
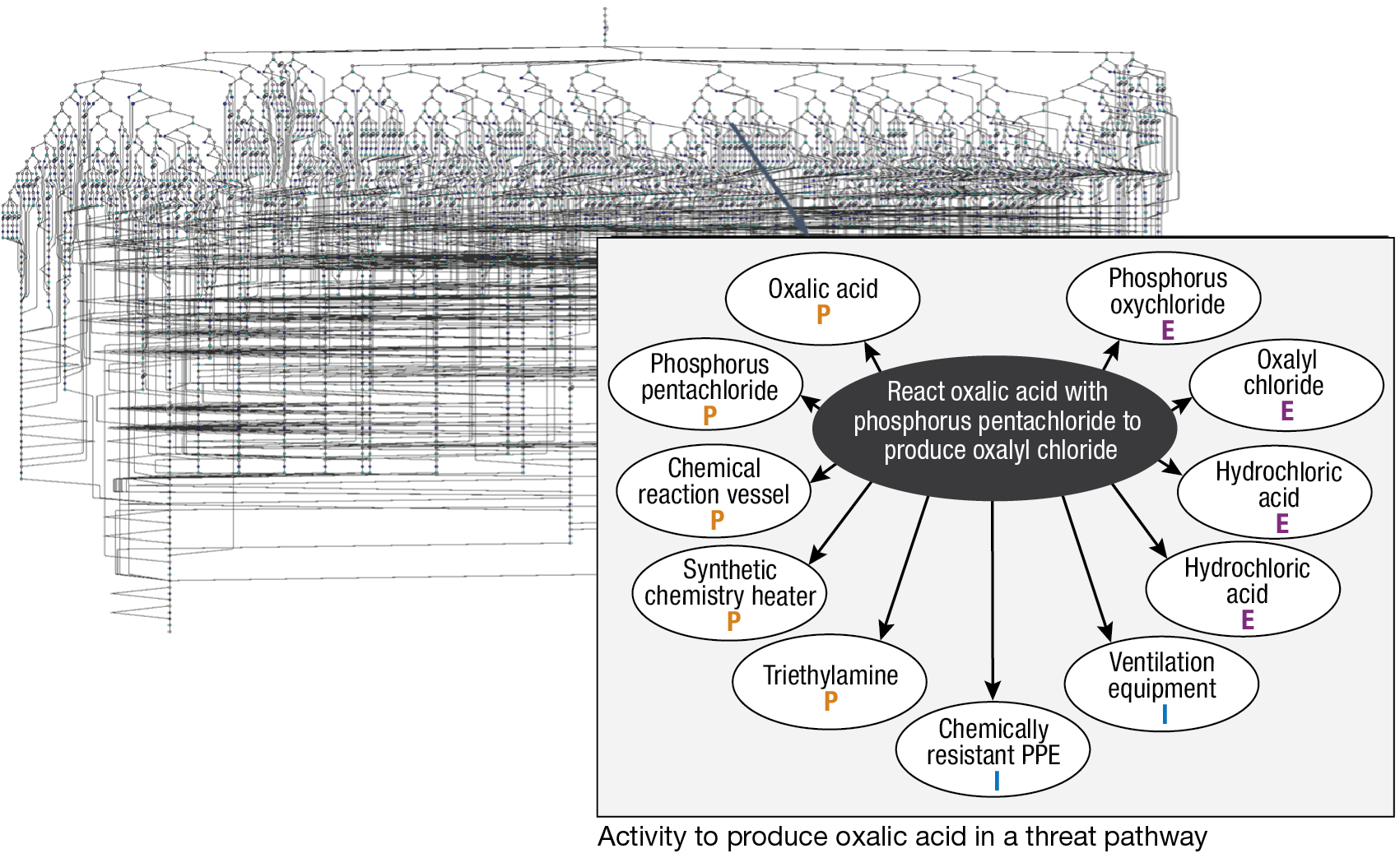
Combining processes, activities, observables and signatures for a single threat agent creates a complex data model that a human would have difficulty understanding as a whole. However, given the structure of the CBRNE-SF, the application interface allows a user to easily query the graph in real time to explore complex relationships among observables, activities, and processes for WMD production, weaponization, and employment. This interface provides deeper insights and more comprehensive answers to complex mission-critical questions. Figure 2 shows an example of a single threat pathway as an illustration of the scale and complexity of more than one hundred of these pathways modeled in the overall graph.